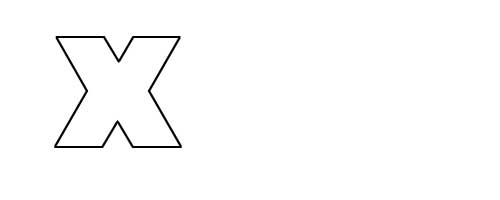Unicode:修饰符 “u” 和 class \p{...}
JavaScript 使用 Unicode 编码 (Unicode encoding)对字符串进行编码。大多数字符使用 2 个字节编码,但这种方式只能编码最多 65536 个字符。
这个范围不足以对所有可能的字符进行编码,这就是为什么一些罕见的字符使用 4 个字节进行编码,比如 ? (数学符号 X)或者 ? (笑脸),一些象形文字等等。
以下是一些字符对应的 unicode 编码:
| 字符 | Unicode | unicode 中的字节数 |
|---|---|---|
| a | 0x0061 | 2 |
| ≈ | 0x2248 | 2 |
| ? | 0x1d4b3 | 4 |
| ? | 0x1d4b4 | 4 |
| ? | 0x1f604 | 4 |
所以像 a 和 ≈ 这样的字符占用 2 个字节,而 ?,? 和 ? 的对应编码则更长,它们具有 4 个字节的长度。
很久以前,当 JavaScript 被发明出来的时候,Unicode 的编码要更加简单:当时并没有 4 个字节长的字符。所以,一部分语言特性在现在仍旧无法对 unicode 进行正确的处理。
比如 length 认为这里的输入有 2 个字符:
alert('?'.length); // 2
alert('?'.length); // 2…但我们可以清楚地认识到输入的字符只有一个,对吧?关键在于 length 把 4 个字节当成了 2 个 2 字节长的字符。这是不对的,因为它们必须被当作一个整体来考虑。(即所谓的“代理伪字符”(surrogate pair),你可以在这里进一步阅读有关的的信息 字符串)。
默认情况下,正则表达式同样把一个 4 个字节的“长字符”当成一对 2 个字节长的字符。正如在字符串中遇到的情况,这将导致一些奇怪的结果。我们将很快在后面的文章中遇到 集合和范围 [...]。
与字符串有所不同的是,正则表达式有一个修饰符 u 被用以解决此类问题。当一个正则表达式使用这个修饰符后,4 个字节长的字符将被正确地处理。同时也能够用上 Unicode 属性(Unicode property)来进行查找了。我们接下来就来了解这方面的内容。
Unicode 属性(Unicode properties)\p{…}
在 Firefox 和 Edge 中缺乏支持
尽管 unicode property 从 2018 年以来便作为标准的一部分, 但 unicode 属性在 Firefox (bug) 和 Edge (bug) 中并没有相应的支持。
目前 XRegExp 这个库提供“扩展”的正则表达式,其中包括对 unicode property 的跨平台支持。
Unicode 中的每一个字符都具有很多的属性。它们描述了一个字符属于哪个“类别”,包含了各种关于字符的信息。
例如,如果一个字符具有 Letter 属性,这意味着这个字符归属于(任意语言的)一个字母表。而 Number 属性则表示这是一个数字:也许是阿拉伯语,亦或者是中文,等等。
我们可以查找具有某种属性的字符,写作 \p{…}。为了顺利使用 \p{…},一个正则表达式必须使用修饰符 u。
举个例子,\p{Letter} 表示任何语言中的一个字母。我们也可以使用 \p{L},因为 L 是 Letter 的一个别名(alias)。对于每种属性而言,几乎都存在对应的缩写别名。
在下面的例子中 3 种字母将会被查找出:英语、格鲁吉亚语和韩语。
let str = "A ბ ㄱ";
alert( str.match(/\p{L}/gu) ); // A,ბ,ㄱ
alert( str.match(/\p{L}/g) ); // null(没有匹配的文本,因为没有修饰符“u”)以下是主要的字符类别和它们对应的子类别:
字母(Letter)
L:小写(lowercase)
Ll修饰(modifier)
Lm,首字母大写(titlecase)
Lt,大写(uppercase)
Lu,其它(other)
Lo。数字(Number)
N:十进制数字(decimal digit)
Nd,字母数字(letter number)
Nl,其它(other)
No。标点符号(Punctuation)
P:链接符(connector)
Pc,横杠(dash)
Pd,起始引用号(initial quote)
Pi,结束引用号(final quote)
Pf,开(open)
Ps,闭(close)
Pe,其它(other)
Po。标记(Mark)
M(accents etc):间隔合并(spacing combining)
Mc,封闭(enclosing)
Me,非间隔(non-spacing)
Mn。符号(Symbol)
S:货币(currency)
Sc,修饰(modifier)
Sk,数学(math)
Sm,其它(other)
So。分隔符(Separator)
Z:行(line)
Zl,段落(paragraph)
Zp,空格(space)
Zs。其它(Other)
C:控制符(control)
Cc,格式(format)
Cf,未分配(not assigned)
Cn,私有(private use)
Co,代理伪字符(surrogate)
Cs。
因此,比如说我们需要小写的字母,就可以写成 \p{Ll},标点符号写作 \p{P} 等等。
也有其它派生的类别,例如:
Alphabetic(Alpha), 包含了字母L, 加上字母数字Nl(例如 Ⅻ – 罗马数字 12),加上一些其它符号Other_Alphabetic(OAlpha)。Hex_Digit包括 16 进制数字0-9,a-f。…等等
Unicode 支持相当数量的属性,列出整个清单需要占用大量的空间,因此在这里列出相关的链接:
列出一个字符的所有属性 https://unicode.org/cldr/utility/character.jsp.
按照属性列出所有的字符 https://unicode.org/cldr/utility/list-unicodeset.jsp.
属性的对应缩写形式:https://www.unicode.org/Public/UCD/latest/ucd/PropertyValueAliases.txt.
以文本格式整理的所有 Unicode 字符,包含了所有的属性:https://www.unicode.org/Public/UCD/latest/ucd/.
实例:16 进制数字
举个例子,让我们来查找 16 进制数字,写作 xFF 其中 F 是一个 16 进制的数字(0…9 或者 A…F)。
一个 16 进制数字可以表示为 \p{Hex_Digit}:
let regexp = /x\p{Hex_Digit}\p{Hex_Digit}/u;
alert("number: xAF".match(regexp)); // xAF实例:中文字符
让我们再来考虑中文字符。
有一个 unicode 属性 Script (一个书写系统),这个属性可以有一个值:Cyrillic,Greek,Arabic,Han (中文)等等,这里是一个完整的列表。
为了实现查找一个给定的书写系统中的字符,我们需要使用 Script=<value>,例如对于西里尔字符:\p{sc=Cyrillic}, 中文字符:\p{sc=Han},等等。
let regexp = /\p{sc=Han}/gu; // returns Chinese hieroglyphs
let str = `Hello Привет 你好 123_456`;
alert( str.match(regexp) ); // 你,好实例:货币
表示货币的字符,例如 $,€,¥,具有 unicode 属性 \p{Currency_Symbol},缩写为 \p{Sc}。
让我们使用这一属性来查找符合“货币,接着是一个数字”的价格文本:
let regexp = /\p{Sc}\d/gu;
let str = `Prices: $2, €1, ¥9`;
alert( str.match(regexp) ); // $2,€1,¥9之后,在文章 量词 `+,*,?` 和 `{n}` 中我们将会了解如何查找包含很多位的数字。
总结
修饰符 u 在正则表达式中提供对 Unicode 的支持。
这意味着两件事:
4 个字节长的字符被以正确的方式处理:被看成单个的字符,而不是 2 个 2 字节长的字符。
Unicode 属性可以被用于查找中
\p{…}。
有了 unicode 属性我们可以查找给定语言中的词,特殊字符(引用,货币)等等。