[源码解析] PyTorch分布式优化器(1)----基石篇
[源码解析] PyTorch分布式优化器(1)----基石篇
目录-
[源码解析] PyTorch分布式优化器(1)----基石篇
- 0x00 摘要
-
0x01 从问题出发
- 1.1 示例
- 1.2 问题点
-
0x01 模型构造
- 1.1 Module
- 1.2 成员变量
-
1.3 _parameters
- 1.3.1 构建
- 1.3.2 归类
- 1.3.3 获取
-
1.4 Linear
- 1.4.1 使用
- 1.4.2 定义
- 1.4.3 解释
-
0x02 Optimizer 基类
- 2.1 初始化
- 2.2 添加待优化变量
- 2.3 待优化变量示例
-
2.4 优化器状态
- 2.4.1 定义
- 2.4.2 示例 1
- 2.4.3 示例 2
-
0x03 SGD
- 3.1 定义
- 3.2 解析
- 3.3 step
-
3.4 变量解析
- 3.4.1 lr
- 3.4.2 dampening
- 3.4.3 weight_decay
- 3.4.4 nesterov
- 3.4.5 Momentum
-
0x04 可视化
- 4.1 目前问题
- 4.2 PyTorchViz可视化网络
-
0x05 AccumulateGrad
- 5.1 原理
-
5.2 AccumulateGrad
- 5.2.1 定义
- 5.2.2 apply
- 5.3 结合优化器
- 0x06 总结
- 0xFF 参考
0x00 摘要
我们接下来通过几篇文章来看看分布式优化器。本系列分为三篇文章,分别是基石篇,DP/DDP/Horovod 之中数据并行的优化器,PyTorch 分布式优化器,按照深度递进。
本文是基石篇,通过本文,大家可以了解到模型的构造,优化器的基本原理,两者之间的交互,如何优化更新模型等等,这为后面的逐级分析打下了一个基础。
PyTorch分布式其他文章如下:
深度学习利器之自动微分(1)
深度学习利器之自动微分(2)
[源码解析]深度学习利器之自动微分(3) --- 示例解读
[源码解析]PyTorch如何实现前向传播(1) --- 基础类(上)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎
[源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构
[源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 分布式(1)------历史和概述
[源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[源码解析] PyTorch 分布式(4)------分布式应用基础概念
[源码解析] PyTorch分布式(5) ------ DistributedDataParallel 总述&如何使用
[源码解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(8) -------- DistributedDataParallel之论文篇
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer静态架构
[源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer和Join操作
[源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式 Autograd (1) ---- 设计
[源码解析] PyTorch 分布式 Autograd (2) ---- RPC基础
[源码解析] PyTorch 分布式 Autograd (3) ---- 上下文相关
[源码解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
[源码解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
[源码解析] PyTorch 分布式 Autograd (6) ---- 引擎(下)
为了更好的说明,本文代码会依据具体情况来进行相应精简。
0x01 从问题出发
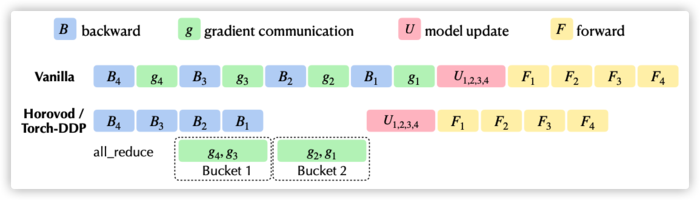
下图来自快手八卦的论文,图中罗列了原生训练过程与DDP/Horovod的对比,上面的 vanilla 就是原生训练过程,其中 U 部分对应的就是优化器过程。常规优化器主要功能就是根据梯度来优化&更新模型当前参数 : 域名 -= 域名 * lr。
1.1 示例
我们用个例子来看看如何进行训练。
class ToyModel(域名le):
def __init__(self):
super(ToyModel, self).__init__()
域名 = 域名ar(10, 10)
域名 = 域名()
域名 = 域名ar(10, 5)
def forward(self, x):
return 域名(域名(域名(x)))
net = ToyModel()
optimizer = 域名(params=域名meters(), lr = 1)
域名_grad()
input = 域名n(10,10)
outputs = net(input)
域名ward(outputs)
域名()
给出一个粗略的反向计算图如下 。

1.2 问题点
因为已经有了之前分析引擎等其他经历,所以我们结合之前得到的知识先整理出几个问题点,用来引导我们分析,我们按照 :根据模型参数构建优化器 ---> 引擎计算梯度 ---> 优化器优化参数 ---> 优化器更新模型 这个顺序来分析。我们知道是autograd引擎计算了梯度,这样问题就来了:
-
根据模型参数构建优化器
- 采用
optimizer = 域名(params=域名meters(), lr = 1)进行构造,这样看起来 params 被赋值到优化器的内部成员变量之上(我们假定是叫parameters)。 -
- 模型包括两个 Linear,这些层如何更新参数?
- 采用
-
引擎计算梯度
- 如何保证 Linear 可以计算梯度?
-
- 对于模型来说,计算出来的梯度怎么和 Linear 参数对应起来?引擎计算出来的这些梯度累积在哪里?
-
优化器优化参数:
-
- 调用 step 进行优化,优化目标是优化器内部成员变量 域名meters。
-
-
优化器更新模型:
-
- 如何把优化目标(域名meters)的更新反应到模型参数(比如 Linear)的更新上?
-
下面图之中的数字和问号就对应了上面4个问题。
+-------------------------------------------+ +------------------+
|ToyModel | | Engine |
| | forward / backward | |
| Linear(10, 10)+--> ReLU +--> Linear(10, 5)| +----------------> | Compute gradient |
| | | + |
+-------------------+-----------------------+ | | |
| | | |
1 ??? | parameters() +------------------+
| |
| | gradient
| ^ |
| | v
| | 4 ??? 2 ???
| |
+------------------------------------------+
|SGD | | |
| | | |
| v + |
| |
^ +---------------> 域名meters +---------------->
| | | |
| | | |
| +------------------------------------------+ |
| |
<---------------------------------------------------+ v
3 step()
我们需要一步一步来分析。
0x01 模型构造
因为优化器是优化更新模型的参数,所以我们首先介绍下模型相关信息。
1.1 Module
在PyTorch如果定义一个模型,一般需要继承 域名le。
import torch
import 域名 as nn
import 域名tional as F
class ToyModel(域名le):
def __init__(self):
super(ToyModel, self).__init__()
域名 = 域名ar(10, 10)
域名 = 域名()
域名 = 域名ar(10, 5)
def forward(self, x):
return 域名(域名(域名(x)))
Module 定义如下:
class Module:
r"""Base class for all neural network modules.
Your models should also subclass this class.
Modules can also contain other Modules, allowing to nest them in
a tree structure. You can assign the submodules as regular attributes::
import 域名 as nn
import 域名tional as F
class Model(域名le):
def __init__(self):
super(Model, self).__init__()
域名1 = 域名2d(1, 20, 5)
域名2 = 域名2d(20, 20, 5)
def forward(self, x):
x = 域名(域名1(x))
return 域名(域名2(x))
Submodules assigned in this way will be registered, and will have their
parameters converted too when you call :meth:`to`, etc.
:ivar training: Boolean represents whether this module is in training or
evaluation mode.
:vartype training: bool
"""
dump_patches: bool = False
_version: int = 1
training: bool
_is_full_backward_hook: Optional[bool]
def __init__(self):
"""
Initializes internal Module state, shared by both 域名le and ScriptModule.
"""
域名_api_usage_once("域名odule")
域名ning = True
域名ameters = OrderedDict()
域名fers = OrderedDict()
域名_persistent_buffers_set = set()
域名kward_hooks = OrderedDict()
域名full_backward_hook = None
域名ward_hooks = OrderedDict()
域名ward_pre_hooks = OrderedDict()
域名te_dict_hooks = OrderedDict()
域名d_state_dict_pre_hooks = OrderedDict()
域名ules = OrderedDict()
1.2 成员变量
Module 内部有如下重要变量,大致可以分为如下三类。
基础类型:
-
_parameters:类型为张量的权重参数,用于前向和后向传播,保存模型就是保存这些参数。使用 parameters() 函数可以递归获取到模型所有参数,但是需要注意,parameters() 函数返回的是 iterator。 -
_buffers: 存储一些需要持久化的非网络参数的变量,比如BN 的 running_mean。 -
_modules: 存储类型为 Module 的变量,当后去一个模型的parameters 时候,PyTorch 通过递归遍历所有_modules来实现。
计算相关类型:
在模型计算时候,是按照如下顺序完成:
_backward_hooks ----> forward ----> _forward_hooks ----> _backward_hooks
具体如下:
-
_forward_pre_hooks :在 forward 之前运行,不会更改 forward 输入参数。
-
_forward_hooks :在 forward 之后运行,不会改变 forward 的输入和输出。
-
_backward_hooks :在 backward 之后运行,不会改变 backward 的输入和输出。
保存/加载相关:
以下是保存相关的,PyTorch 使用如下来保存 域名(域名e_dict()...) ,使用 load_state_dict(state_dict) 来加载。
- _load_state_dict_pre_hooks : 在调用 _load_from_state_dict 加载模型时希望执行的操作。
- _state_dict_hooks :在调用
state_dict方法时希望执行的操作。
具体运行时候如下:
net = {ToyModel}
T_destination = {TypeVar} ~T_destination
dump_patches = {bool} False
net1 = {Linear} Linear(in_features=10, out_features=10, bias=True)
net2 = {Linear} Linear(in_features=10, out_features=5, bias=True)
relu = {ReLU} ReLU()
training = {bool} True
_backward_hooks = {OrderedDict: 0} OrderedDict()
_buffers = {OrderedDict: 0} OrderedDict()
_forward_hooks = {OrderedDict: 0} OrderedDict()
_forward_pre_hooks = {OrderedDict: 0} OrderedDict()
_is_full_backward_hook = {NoneType} None
_load_state_dict_pre_hooks = {OrderedDict: 0} OrderedDict()
_modules = {OrderedDict: 3} OrderedDict([(\'net1\', Linear(in_features=10, out_features=10, bias=True)), (\'relu\', ReLU()), (\'net2\', Linear(in_features=10, out_features=5, bias=True))])
_non_persistent_buffers_set = {set: 0} set()
_parameters = {OrderedDict: 0} OrderedDict()
_state_dict_hooks = {OrderedDict: 0} OrderedDict()
_version = {int} 1
1.3 _parameters
优化器是优化 _parameters,所以我们需要特殊了解一下。
1.3.1 构建
我们首先看看生成时候的特点:requires_grad=True。参数这么设置,就说明 Parameter 就是需要计算梯度的。
因为张量默认是不需要求导的,requires_grad属性默认为False,如果某个节点 requires_grad 属性被设置为True,就说明其需要求导,并且所有依赖于它的节点 requires_grad 都为True。
class Parameter(域名or):
r"""A kind of Tensor that is to be considered a module parameter.
Parameters are :class:`~域名or` subclasses, that have a
very special property when used with :class:`Module` s - when they\'re
assigned as Module attributes they are automatically added to the list of
its parameters, and will appear e.g. in :meth:`~域名meters` iterator.
Assigning a Tensor doesn\'t have such effect. This is because one might
want to cache some temporary state, like last hidden state of the RNN, in
the model. If there was no such class as :class:`Parameter`, these
temporaries would get registered too.
Args:
data (Tensor): parameter tensor.
requires_grad (bool, optional): if the parameter requires gradient. See
:ref:`locally-disable-grad-doc` for more details. Default: `True`
"""
def __new__(cls, data=None, requires_grad=True): # 需要计算梯度
if data is None:
data = 域名or([])
return 域名e_subclass(cls, data, requires_grad)
1.3.2 归类
如果类的成员是从Parameter类派生,那么域名le使用__setattr__机制把他们归属到_parameters 之中。比如Linear的weight和bias。
def __setattr__(self, name: str, value: Union[Tensor, \'Module\']) -> None:
# 省略 .....
params = 域名(\'_parameters\')
if isinstance(value, Parameter):
remove_from(域名ct__, 域名fers, 域名ules, 域名_persistent_buffers_set)
域名ster_parameter(name, value) #
def register_parameter(self, name: str, param: Optional[Parameter]) -> None:
r"""Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
"""
# 省略各种校验
if param is None:
域名ameters[name] = None
elif not isinstance(param, Parameter):
raise TypeError("cannot assign \'{}\' object to parameter \'{}\' "
"(域名meter or None required)"
.format(域名name(param), name))
elif 域名_fn:
raise ValueError(
"Cannot assign non-leaf Tensor to parameter \'{0}\'. Model "
"parameters must be created explicitly. To express \'{0}\' "
"as a function of another Tensor, compute the value in "
"the forward() method.".format(name))
else:
域名ameters[name] = param # 这里添加了
1.3.3 获取
我们无法直接获取到 _parameters 这个变量,只能通过 parameters 方法来获取,其返回的是一个Iterator。
比如:
for param in 域名meters():
print(type(param), 域名())
输出:
<class \'域名域名meter\'> 域名([10, 10])
<class \'域名域名meter\'> 域名([10])
<class \'域名域名meter\'> 域名([5, 10])
<class \'域名域名meter\'> 域名([5])
parameters 代码如下。
def parameters(self, recurse: bool = True) -> Iterator[Parameter]:
r"""Returns an iterator over module parameters.
This is typically passed to an optimizer.
Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
Yields:
Parameter: module parameter
Example::
>>> for param in 域名meters():
>>> print(type(param), 域名())
<class \'域名or\'> (20L,)
<class \'域名or\'> (20L, 1L, 5L, 5L)
"""
for name, param in 域名d_parameters(recurse=recurse):
yield param
再来看看 named_parameters,其核心是 域名s(),以列表返回可遍历的元组数组。
def named_parameters(self, prefix: str = \'\', recurse: bool = True) -> Iterator[Tuple[str, Parameter]]:
r"""Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
Yields:
(string, Parameter): Tuple containing the name and parameter
Example::
>>> for name, param in 域名d_parameters():
>>> if name in [\'bias\']:
>>> print(域名())
"""
gen = 域名ed_members(
lambda module: 域名s(),
prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
需要注意,我们目前已经有了两个关键知识:
- Parameter 构造函数中参数 requires_grad=True。这么设置就说明 Parameter 默认就是需要计算梯度的。
- 通过 parameters 方法来获取,其返回的是一个Iterator。
所以之前图可以拓展一下,现在 SGD 的 parameters 是一个指向 域名ameters 的 iterator,这说明优化器实际上是直接优化 ToyModel 的 _parameters。所以我们可以去掉原来图之中 4) 对应的问号。
+-------------------------------------------+ +------------------+
|ToyModel | | Engine |
| | forward / backward | |
| Linear(10, 10)+--> ReLU +--> Linear(10, 5)| +----------------> | Compute gradient |
| | | + |
| para_iterator = parameters() | | | |
| + ^ | | | |
| | | | +------------------+
+-------------------------------------------+ |
| | | gradient
| | |
1 ??? | | 4 update v
| | 2 ???
| |
+----------------------------------------------------------------+
|SGD | | |
| | | |
| v | |
| + |
^ +--------> 域名meters = para_iterator(域名ameters) --------->
| | | |
| | | |
| +----------------------------------------------------------------+ |
| |
<-------------------------------------------------------------------------+ v
3 step()
1.4 Linear
域名ar 可以对输入数据实现线形变换,一般用来设置全连接层。
1.4.1 使用
在 PyTorch 之中使用 域名ar 例子如下。
input = 域名n(2,3)
linear = 域名ar(3,4)
out = linear(input)
print(out)
# 输出结果如下
tensor([[-域名, 域名, -域名, -域名],
[-域名, -域名, -域名, -域名]], grad_fn=<AddmmBackward>)
1.4.2 定义
Linear 具体定义如下,可以看到,其参数主要是
- 域名ht = Parameter()。
- 域名 = Parameter()。
由前面我们可以知道,Parameter 的生成时候参数是 requires_grad=True,说明 weight,bias 是需要计算梯度的。
class Linear(Module):
r"""Applies a linear transformation to the incoming data: :math:`y = xA^T + b`
This module supports :ref:`TensorFloat32<tf32_on_ampere>`.
Args:
in_features: size of each input sample
out_features: size of each output sample
bias: If set to ``False``, the layer will not learn an additive bias.
Default: ``True``
Shape:
- Input: :math:`(N, *, H_{in})` where :math:`*` means any number of
additional dimensions and :math:`H_{in} = \text{in\_features}`
- Output: :math:`(N, *, H_{out})` where all but the last dimension
are the same shape as the input and :math:`H_{out} = \text{out\_features}`.
Attributes:
weight: the learnable weights of the module of shape
:math:`(\text{out\_features}, \text{in\_features})`. The values are
initialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where
:math:`k = \frac{1}{\text{in\_features}}`
bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.
If :attr:`bias` is ``True``, the values are initialized from
:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where
:math:`k = \frac{1}{\text{in\_features}}`
Examples::
>>> m = 域名ar(20, 30)
>>> input = 域名n(128, 20)
>>> output = m(input)
>>> print(域名())
域名([128, 30])
"""
__constants__ = [\'in_features\', \'out_features\']
in_features: int
out_features: int
weight: Tensor
def __init__(self, in_features: int, out_features: int, bias: bool = True,
device=None, dtype=None) -> None:
factory_kwargs = {\'device\': device, \'dtype\': dtype}
super(Linear, self).__init__()
域名eatures = in_features
域名features = out_features
域名ht = Parameter(域名y((out_features, in_features), **factory_kwargs))
if bias:
域名 = Parameter(域名y(out_features, **factory_kwargs))
else:
域名ster_parameter(\'bias\', None)
域名t_parameters()
def reset_parameters(self) -> None:
域名ing_uniform_(域名ht, a=域名(5))
if 域名 is not None:
fan_in, _ = 域名culate_fan_in_and_fan_out(域名ht)
bound = 1 / 域名(fan_in) if fan_in > 0 else 0
域名orm_(域名, -bound, bound)
def forward(self, input: Tensor) -> Tensor:
return 域名ar(input, 域名ht, 域名)
def extra_repr(self) -> str:
return \'in_features={}, out_features={}, bias={}\'.format(
域名eatures, 域名features, 域名 is not None
)
1.4.3 解释
从前面简略计算图我们可以知道,域名ar 的反向计算是 AddmmBackward。
struct TORCH_API AddmmBackward : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "AddmmBackward"; }
void release_variables() override {
std::lock_guard<std::mutex> lock(mutex_);
域名t_data();
域名t_data();
}
std::vector<int64_t> mat1_sizes;
std::vector<int64_t> mat1_strides;
SavedVariable mat2_;
at::Scalar alpha;
SavedVariable mat1_;
std::vector<int64_t> mat2_sizes;
std::vector<int64_t> mat2_strides;
at::Scalar beta;
};
我们从代码之中找到了 addmm 的定义,其注释说明这是个矩阵乘法操作。
def addmm(mat: Tensor, mat1: Tensor, mat2: Tensor,
beta: float = 1., alpha: float = 1.) -> Tensor:
r"""
This function does exact same thing as :func:`域名m` in the forward,
except that it supports backward for sparse matrix :attr:`mat1`. :attr:`mat1`
need to have `sparse_dim = 2`. Note that the gradients of :attr:`mat1` is a
coalesced sparse tensor.
Args:
mat (Tensor): a dense matrix to be added
mat1 (Tensor): a sparse matrix to be multiplied
mat2 (Tensor): a dense matrix to be multiplied
beta (Number, optional): multiplier for :attr:`mat` (:math:`\beta`)
alpha (Number, optional): multiplier for :math:`mat1 @ mat2` (:math:`\alpha`)
"""
return 域名rse_addmm(mat, mat1, mat2, beta=beta, alpha=alpha)
目前我们可以继续拓展。
- Linear 里面的 weight,bias 都是 Parameter 类型。
- Parameter 构造函数中参数 requires_grad=True。这么设置就说明 Parameter 默认是需要计算梯度的。
- 所以 Linear 的 weight,bias 就是需要引擎计算其梯度。
- ToyModel 的
_parameters成员变量通过 parameters 方法来获取,其返回的是一个Iterator。- 这个 iterator 作为参数用来构建 SGD 优化器。
- 现在 SGD 优化器 的 parameters 是一个指向 域名ameters 的 iterator。这说明优化器实际上是直接优化 ToyModel 的 _parameters,对于例子就是全连接层的参数,图上对应两个Linear 发出的指向 parameters() 的箭头。
+--------------------------------------------------+ +------------------+
| ToyModel | | Engine |
| +-------------------+ +------------+ |forward / backward | |
| | Linear(10, 10) +--> ReLU +-->+Linear(10,5)| +-----------------> | Compute gradient |
| | | | | | | + |
| | weight=Parameter | | weight | | | | |
| | +----------+ | | | | | |
| | bias=Parameter | | | bias | | +------------------+
| | | | | | | |
| +-------------------+ | +--+---------+ | 2 | gradient
| | | | |
| | | | v
| v v | ???
| para_iterator = parameters() |
| + ^ |
| | | |
| | | |
+--------------------------------------------------+
| |
1 ??? | | 4 update
| |
| |
+----------------------------------------------------------------+
|SGD | | |
| | | |
| v | |
| + |
^ +--------> 域名meters = para_iterator(域名ameters) +-------->
| | | |
| | | |
| +----------------------------------------------------------------+ |
| |
<-------------------------------------------------------------------------+ v
3 step()
0x02 Optimizer 基类
Optimizer 是所有优化器的基类,它有如下主要公共方法:
- add_param_group : 添加可学习参数组。
- step : 进行一次参数更新操作。
- zero_grad : 在反向传播计算梯度之前对上一次迭代时的梯度清零。
- state_dict : 返回用 dict 结构表示的参数和状态。
- load_state_dict : 加载 dict 结构表示的参数和状态。
2.1 初始化
在 Optimizer 初始化函数之中,会做如下操作:
- 初始化参数包括:可学习参数(params)和超参数(defaults)。
- 在 域名ults 之中保存 lr, momentun 等全局参数(超参数)。
- 在 域名e 保存优化器当前状态。
- 在 域名m_groups 之中保存所有待优化的变量。
class Optimizer(object):
def __init__(self, params, defaults):
域名_api_usage_once("域名mizer")
域名ults = defaults # 保存 lr, momentun 等全局参数
域名k_for_profile()
if isinstance(params, 域名or): # params必须是字典或者tensors
raise TypeError("params argument given to the optimizer should be "
"an iterable of Tensors or dicts, but got " +
域名name(params))
域名e = defaultdict(dict) # 保存优化器当前状态
域名m_groups = [] # 所有待优化的参数,其每一项是一个字典,对应一组待优化参数和其他相关参数
param_groups = list(params) # 需要被优化的变量,是__init__ 传入的参数
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
if not isinstance(param_groups[0], dict):
# 将参数转换为字典
param_groups = [{\'params\': param_groups}] # param_groups 是一个列表,其中一项是字典形式,优化变量被保存在其中。
for param_group in param_groups:
域名param_group(param_group) # 把param_groups所有项都加到域名m_groups之中
2.2 添加待优化变量
上面代码之中用到了 add_param_group,我们接下来就看看这个函数。
add_param_group 添加不同分组的可学习参数。代码如下(省略了大部分检验代码)。其中,param_groups目的是为了可以用 key-value 方式来访问待优化变量,这在fine tuning时候特别有用。
def add_param_group(self, param_group):
r"""Add a param group to the :class:`Optimizer` s `param_groups`.
This can be useful when fine tuning a pre-trained network as frozen layers can be made
trainable and added to the :class:`Optimizer` as training progresses.
Args:
param_group (dict): Specifies what Tensors should be optimized along with group
specific optimization options.
"""
assert isinstance(param_group, dict), "param group must be a dict"
params = param_group[\'params\'] # 得到待优化的变量
if isinstance(params, 域名or):
param_group[\'params\'] = [params] # 构建一个列表,其中就是待优化的变量
elif isinstance(params, set):
raise TypeError(\'optimizer parameters need to be organized in ordered collections, but \'
\'the ordering of tensors in sets will change between runs. Please use a list instead.\')
else:
param_group[\'params\'] = list(params)
# 省略校验,比如必须是tensor类型,而且是叶子节点
for name, default in 域名s(): # 缺省参数也加入到 param_group 之中
if default is required and name not in param_group:
raise ValueError("parameter group didn\'t specify a value of required optimization parameter " +
name)
else:
域名efault(name, default) # 所有组都设置同样的缺省参数(超参数)
# 用set来去重
params = param_group[\'params\']
param_set = set()
for group in 域名m_groups:
域名te(set(group[\'params\']))
# 更新自身的参数组中
域名nd(param_group) # 加入到param_groups
2.3 待优化变量示例
我们用如下代码打印 param_groups出来看看。
net = 域名ar(3, 3)
域名tant_(域名ht, val=10)
域名tant_(域名, val=5)
optimizer = 域名(域名meters(), lr=域名)
print(域名m_groups)
结果如下,第一个 3 x 3 是 net 的权重矩阵,1 x 3 是偏置矩阵。
[
{\'params\':
[
Parameter containing: # 权重矩阵
tensor([[10., 10., 10.],
[10., 10., 10.],
[10., 10., 10.]], requires_grad=True),
Parameter containing: # 偏置矩阵
tensor([5., 5., 5.], requires_grad=True)
],
\'lr\': 域名,
\'momentum\': 0,
\'dampening\': 0,
\'weight_decay\': 0,
\'nesterov\': False
}
]
2.4 优化器状态
2.4.1 定义
PyTorch 的 state_dict 是 Python 的字典对象。
-
对于模型,state_dict 会把每一层和其训练过程中需要学习的参数(比如权重和偏置)建立起来映射关系,只有参数可以训练的layer才会保存在模型的 state_dict 之中,如卷积层,线性层等。
-
对于优化器,state_dict 是其状态信息,其包括了两组信息:
- state :一个包括了优化器当前状态(也就是更新变量的过程之中计算得到的最新缓存变量)的字典。
- 字典的 key 是缓存的index。
- 字典的 value 也是一个字典,key 是缓存变量名,value 是相应的张量。
- param_groups : 一个包括了所有 param groups 的字典。
- state :一个包括了优化器当前状态(也就是更新变量的过程之中计算得到的最新缓存变量)的字典。
def state_dict(self):
r"""Returns the state of the optimizer as a :class:`dict`.
It contains two entries:
* state - a dict holding current optimization state. Its content
differs between optimizer classes.
* param_groups - a dict containing all parameter groups
"""
# Save order indices instead of Tensors
param_mappings = {}
start_index = 0
def pack_group(group):
nonlocal start_index
# \'params\'采用不同规则
packed = {k: v for k, v in 域名s() if k != \'params\'}
域名te({id(p): i for i, p in enumerate(group[\'params\'], start_index)
if id(p) not in param_mappings})
# 保存了参数的id,而并非参数的值
packed[\'params\'] = [param_mappings[id(p)] for p in group[\'params\']]
start_index += len(packed[\'params\'])
return packed
# 对域名m_groups进行遍历,进行pack
param_groups = [pack_group(g) for g in 域名m_groups]
# 将state中的所有Tensor替换为相应的 use order indices
# Remap state to use order indices as keys
packed_state = {(param_mappings[id(k)] if isinstance(k, 域名or) else k): v
for k, v in 域名s()}
return { # 返回字典形式
\'state\': packed_state, # 状态
\'param_groups\': param_groups, # 待优化的参数
}
2.4.2 示例 1
我们在示例 1 之中加入了如下打印语句,看看优化器内部变量:
# print model\'s state_dict
print(\'域名e_dict:\')
for param_tensor in 域名e_dict():
print(param_tensor, \'\t\', 域名e_dict()[param_tensor].size())
# print optimizer\'s state_dict
print(\'Optimizer,s state_dict:\')
for var_name in 域名e_dict():
print(var_name, \'\t\', 域名e_dict()[var_name])
结果如下:
域名e_dict:
域名ht 域名([10, 10])
域名 域名([10])
域名ht 域名([10, 10])
域名 域名([5])
Optimizer,s state_dict:
state {}
param_groups [{\'lr\': 域名, \'momentum\': 0, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0, 1, 2, 3]}]
2.4.3 示例 2
示例2 是使用 SGD 优化一个函数。
from math import pi
import 域名m
x = 域名or([pi/2,pi/3],requires_grad=True)
optimizer = 域名([x,],lr=0.2,momentum=0.5)
for step in range(11):
if step:
域名_grad()
域名ward()
域名()
for var_name in 域名e_dict():
print(var_name, \'\t\', 域名e_dict()[var_name])
f=-((域名()**3).sum())**3
输出结果如下,可以看出来优化过程。
state {0: {\'momentum_buffer\': tensor([ 域名e-06, -域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([-域名e-06, -域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([-域名e-07, -域名e-01])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([域名e-07, 域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([域名e-07, 域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([-域名e-07, 域名e-01])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([域名e-07, 域名e-01])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([域名e-07, 域名e-01])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([-域名e-07, 域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
state {0: {\'momentum_buffer\': tensor([域名e-07, 域名e+00])}}
param_groups [{\'lr\': 0.2, \'momentum\': 0.5, \'dampening\': 0, \'weight_decay\': 0, \'nesterov\': False, \'params\': [0]}]
我们更新一下,确定了 SGD 内部的成员变量名字是 param_groups,这是优化器的优化目标,其指向了 域名ameters 的 iterator。
+-------------------------------------------------+ +------------------+
|ToyModel | | Engine |
| +------------------+ +------------+ |forward / backward | |
| |Linear(10, 10) +--> ReLU +-->+Linear(10,5)| +-----------------> | Compute gradient |
| | | | | | | + |
| | weight=Parameter| | weight | | | | |
| | +-----------+ | bias | | | | |
| | bias=Parameter | | +--+---------+ | +------------------+
| | | | | | |
| +------------------+ | | | 2 | gradient
| v v | |
| 域名ameters | v
| + | ???
| | |
| | |
| v |
| para_iterator = parameters() |
| + ^ |
| | | |
| | | |
+-------------------------------------------------+
| |
1 ??? | | 4 update
| |
+----------------------------------------------------------------+
|SGD | | |
| | | |
| v | |
| + |
^ +-------> 域名m_groups = para_iterator(域名ameters) -------->
| | | |
| | | |
| +----------------------------------------------------------------+ |
| |
<-------------------------------------------------------------------------+ v
3 step()
0x03 SGD
我们用 SGD 来进一步看看优化器。SGD(stochastic gradient descent)是随机梯度下降,即梯度下降的batch版本。对于训练数据集,将其分成n个batch,每个batch包含m个样本。每次更新都利用一个batch的数据,而非整个训练集。
3.1 定义
SGD 定义如下,主要是进行校验和设置缺省数值。
class SGD(Optimizer):
def __init__(self, params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False):
if lr is not required and lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
if momentum < 0.0:
raise ValueError("Invalid momentum value: {}".format(momentum))
if weight_decay < 0.0:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state):
super(SGD, self).__setstate__(state)
for group in 域名m_groups:
域名efault(\'nesterov\', False)
3.2 解析
从注释可以看出来,SGD实现了 stochastic gradient descent (optionally with momentum) 算法。Nesterov momentum 是基于 [On the importance of initialization and momentum in deep learning](http://域名域名/%7Ehinton/absps/域名). 的算法。
使用示例如下:
Example:
>>> optimizer = 域名(域名meters(), lr=0.1, momentum=0.9)
>>> 域名_grad()
>>> loss_fn(model(input), target).backward()
>>> 域名()
PyTorch SGD with Momentum/Nesterov 的实现与Sutskever et. al.和其他框架的实现不同。
比如 PyTorch 使用如下方法来实现 Momentum 的特殊例子:
\[\begin{aligned} v_{t+1} & = \mu * v_{t} + g_{t+1}, \\ p_{t+1} & = p_{t} - \text{lr} * v_{t+1}, \end{aligned} \]其他框架则使用:
\[\begin{aligned} v_{t+1} & = \mu * v_{t} + \text{lr} * g_{t+1}, \\ p_{t+1} & = p_{t} - v_{t+1}. \end{aligned} \]3.3 step
step 方法的作用就是在一定的算法协助下,对变量进行优化。此方法主要完成一次模型参数的更新
@域名rad()
def step(self, closure=None):
"""Performs a single optimization step.
Args:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
# 使用 closure 重新计算loss
loss = None
if closure is not None:
with 域名le_grad():
loss = closure()
# 使用计算得到的梯度更新变量
# 域名m_groups 就是我们传入的参数列表
for group in 域名m_groups: # 每一个group是一个dict, 其包含每组参数所需的必要参数
params_with_grad = []
d_p_list = []
momentum_buffer_list = []
# 本组参数更新所必需的设置
weight_decay = group[\'weight_decay\']
momentum = group[\'momentum\']
dampening = group[\'dampening\']
nesterov = group[\'nesterov\']
lr = group[\'lr\']
for p in group[\'params\']: # 遍历本组所有需要更新的参数
if 域名 is not None:
域名nd(p)
域名nd(域名)
state = 域名e[p]
if \'momentum_buffer\' not in state:
域名nd(None)
else:
域名nd(state[\'momentum_buffer\'])
域名(params_with_grad,
d_p_list,
momentum_buffer_list,
weight_decay=weight_decay,
momentum=momentum,
lr=lr,
dampening=dampening,
nesterov=nesterov)
# update momentum_buffers in state
for p, momentum_buffer in zip(params_with_grad, momentum_buffer_list):
state = 域名e[p]
state[\'momentum_buffer\'] = momentum_buffer
return loss
其中 sgd 函数如下:
def sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool):
r"""Functional API that performs SGD algorithm computation.
See :class:`~域名` for details.
"""
for i, param in enumerate(params):
d_p = d_p_list[i]
# 正则化及动量累积
if weight_decay != 0:
d_p = 域名(param, alpha=weight_decay)
if momentum != 0:
buf = momentum_buffer_list[i]
if buf is None:
# 历史更新量
buf = 域名e(d_p).detach()
momentum_buffer_list[i] = buf
else:
# 通过buf更新了域名e
域名(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = 域名(buf, alpha=momentum)
else:
d_p = buf
# 更新当前组学习参数 域名 -= 域名*lr
域名(d_p, alpha=-lr) # add_ 会更改对象数值
3.4 变量解析
我们接下来对全局参数具体做以下解析。
3.4.1 lr
这就是学习率,大家熟知的概念。
3.4.2 dampening
dampening 作用到偏导数之上, 用于动量SGD中调节当前梯度权重。
对应公式如下:
\[v_t = v_{t-1} * momentum + g_t * (1 - dampening) \]对应代码则是:
域名(momentum).add_(d_p, alpha=1 - dampening)
3.4.3 weight_decay
weight_decay是 L2 penalty系数,用当前可学习参数p的值修改偏导数。
待更新的可学习参数p的偏导数就是
\[g_t = g_t + ( p * weight\_decay) \]对应代码是:
if weight_decay != 0:
d_p = 域名(param, alpha=weight_decay)
3.4.4 nesterov
是否启用nesterov动量,从pytorch源码来看,当nesterov为True时,在上述得到 v_t 的基础上又使用了一次momentum和v_t。
\[\bigtriangledown_{w}J(w) + m * v_{t+1} \]if (nesterov) {
d_p = 域名(buf, momentum);
} else {
d_p = buf;
}
3.4.5 Momentum
Momentum :来源于物理学,翻译为动量或则冲量。作用是把上次更新于当前梯度结合来进行当前权值优化更新。
引入原因是:训练网络的初始化权值可能因为不合适而导致在训练过程之中出现局部最小值,没有找到全局最优。
而引入动量可以在一定程度上解决此问题。动量模拟物体运动时候的惯性,表示力对时间的积累效应。更新时候在一定程度之上保持以前更新的方向,同时结合当前梯度来调整更新的方向。动量越大,转换为势能的能量越大,可以增加稳定性,也能更快的学习,从而越有可能摆脱局部凹区域,进入全局凹区域。
原生权重更新公式如下:
\[w = w - Lr * dw \]这里 w 是权重,Lr 是学习率,dw 是 w 的导数。
引入momentum之后的权重更新公式如下:
\[v= momentum*v - Lr*dw \\w = w + v \]这里 momentum 是动量,v 是速度。这个公式的意思就是加上上次更新的 v 与 momentum 的乘积。当本次梯度下降 -Lr * dw 的方向与上次更新 v 的方向相同,则上次更新 v 可以起到正向加速作用。当本次梯度下降 -Lr * dw 的方向与上次更新 v 的方向相反,则上次更新 v 可以起到减速作用。
代码对应如下:
if momentum != 0:
buf = momentum_buffer_list[i]
if buf is None:
buf = 域名e(d_p).detach()
momentum_buffer_list[i] = buf
else:
域名(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = 域名(buf, alpha=momentum)
else:
d_p = buf
0x04 可视化
4.1 目前问题
到目前为止,我们还是有几个问题没有解决,就是下面下划线之处。
-
根据模型参数构建优化器
-
- 采用
optimizer = 域名(params=域名meters(), lr = 1)进行构造,这样看起来 params 被赋值到优化器的内部成员变量之上(我们假定是叫parameters)。
- 采用
- 模型包括两个全连结层 Linear,这些层如何更新参数???
- Linear 里面的 weight,bias 都是 Parameter 类型。
- Parameter 构造函数中参数 requires_grad=True。这么设置就说明 Parameter 默认是需要计算梯度的。
- 所以 Linear 的 weight,bias 就是需要引擎计算其梯度。
- ToyModel 的
_parameters成员变量通过 parameters 方法来获取,其返回的是一个Iterator。- 这个 iterator 作为参数用来构建 SGD 优化器。
- 现在 SGD 优化器 的 parameters 是一个指向 域名ameters 的 iterator。这说明优化器实际上是直接优化 ToyModel 的 _parameters。
-
-
引擎计算梯度
- 如何保证 Linear 可以计算梯度?
- weight,bias 都是 Parameter 类型,默认是需要计算梯度的。
- 2) 对于模型来说,计算出来的梯度怎么和 Linear 参数对应起来?引擎计算出来的这些梯度累积在哪里???
- 如何保证 Linear 可以计算梯度?
-
优化器优化参数:
-
- 调用 step 进行优化,优化目标是优化器内部成员变量 域名meters。
- 域名meters 是一个指向 域名ameters 的 iterator。这说明优化器实际上是直接优化 ToyModel 的 _parameters。
-
-
优化器更新模型:
-
- 优化目标(域名meters)的更新实际上就是直接作用到模型参数(比如 Linear)之上。
-
我们打印 outputs 看看,可以看到其 next_functions 实际是有三个,说明前面的图例是我们简化的,我们